

频年来,基于大讲话模子的多智能体系统(LLM-based Multi-Agent Systems, MAS)被普通用于复杂推理任务。典型作念法是让多个 agent 自在生成并通过投票或诡辩等机制团员有盘算,从而在算术推理、学问推断与专科问答中擢升准确率。
跟着 test-time compute(推理时计算)成为常见的能力擢升本领,一个当然的问题随之出现:MAS 是否能通过不休增多 agent 数目而捏续变强?直观上,这个设想似乎缔造:雷同 ensemble 或 self-consistency 的「屡次采样 + 团员」常常能提高消散正确谜底的概率。
来自上海交通大学、UC Berkeley、加州理工学院以及约翰・霍普金斯大学的联接商论说文 Understanding Agent Scaling in LLM-Based Multi-Agent Systems via Diversity 标明:多智能体系统「扩不动」的果真原因,并不是 Agent 不够多,而是信息冗余。 系统实验发现,单纯堆限制收益飞速困难,而引入千般性不错显贵减慢实足、以更少的 Agent 得回更强的性能。

论文标题:Understanding Agent Scaling in LLM-Based Multi-Agent Systems via Diversity
GitHub 代码:https://github.com/SafeRL-Lab/Agent-Scaling
同质彭胀的失效:
限制带来的收益飞速实足
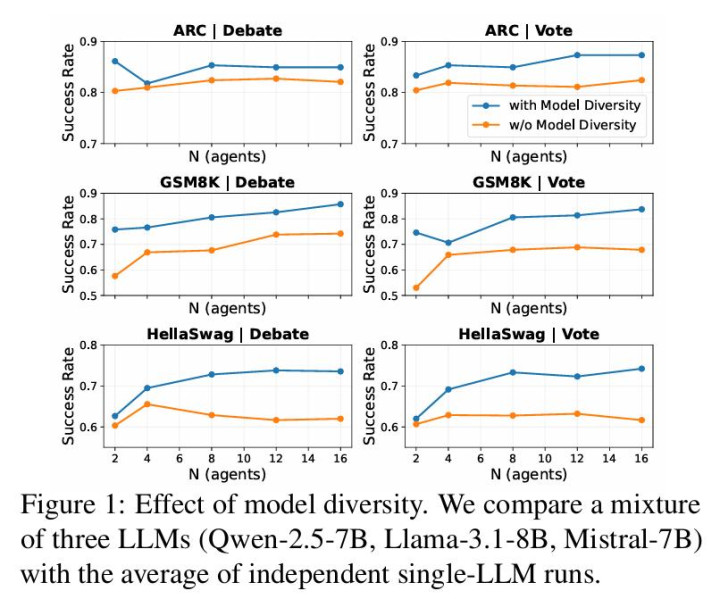
论文当先胜利磨真金不怕火「增多 agent 数是否有用」。在同质缔造下,整个 agent 分享疏通底座模子与系统请示(无 persona 互异,建树一致),汲取两类常见合作机制:
Vote:单轮自在生成后大齐投票;
Debate:多轮交互后再给出最终谜底(交互 4 轮)。
仅改变 agent 数 N,在 7 个基准任务(GSM8K、ARC、Formal Logic、TruthfulQA、HellaSwag、WinoGrande、Pro Medicine)上评估。

扫尾在不同任务与模子上高度一致:当 N 从 1 增至 2 或 4 时,性能不竭彰着擢升;但赓续增多 N 后,准确率飞速参加平台期,旯旮收益接近 0,部分缔造以致出现回落。这确认:在同质建树下,单纯堆叠更多 agent calls 并不行捏续注入新的有用信息。
千般性带来的对照气候:
一丝异质 agent 胜过大限制同质系统
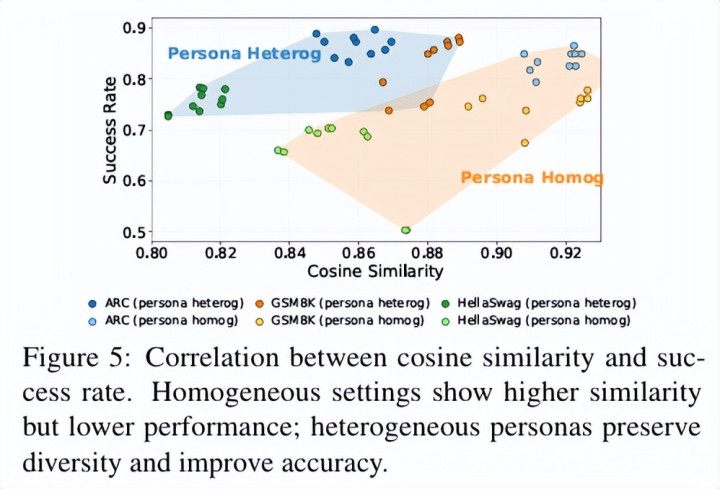
与同质彭胀的快速实足酿成领悟对比的是,千般性建树下的实验扫尾。论文进一步比拟了两类系统:一类由覆没模子屡次自在驱动组成,另一类则由不同 backbone 模子或不同 persona prompt 组成。在匹配计算预算(固定总 agent calls)的前提下,异质系统在同预算下合座更高,而况在更大的 N 上仍能保捏增益。
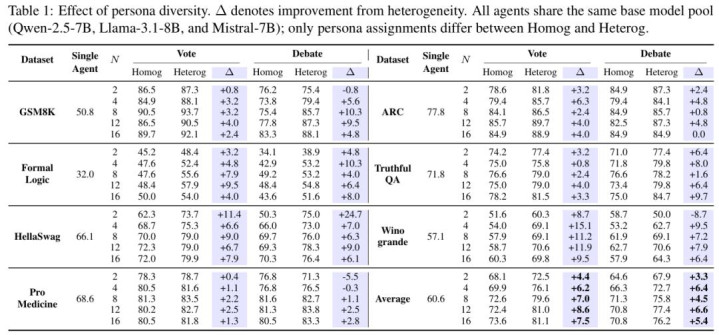
为了更系统地清醒这一气候,作家在实验中将千般性拆解为不同开头,包括 persona 千般性、模子千般性,以及二者结合的彻底千般性,并在搭伙缔造下进行对比。
在 GSM8K、ARC、HellaSwag、TruthfulQA 等七个基准任务上,开云app作家系统比拟了:
Agent 彻底一致(L1)
Agent Persona 千般性(L2)
Base Model 千般性(L3)
Persona千般性兼Base Model千般性(L4)
扫尾显现,每引入一层新的千般性,系统合座性能齐会显贵上移;其中,模子千般性和 persona 千般性各自齐具有自在孝顺,而二者结合时扫尾最为显贵。
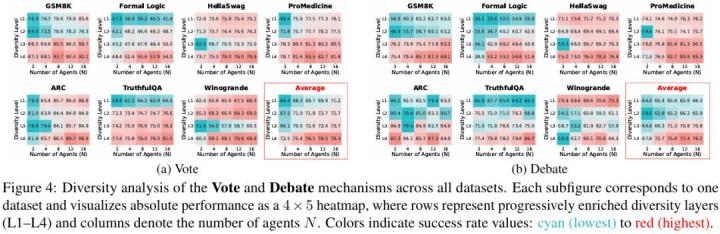
这一趋势在遵守层面体现得尤为彰着:在多个任务上,仅使用 2 个彻底异质的 agent,就不错达到以致卓著 16 个同质 agent 的平均性能。
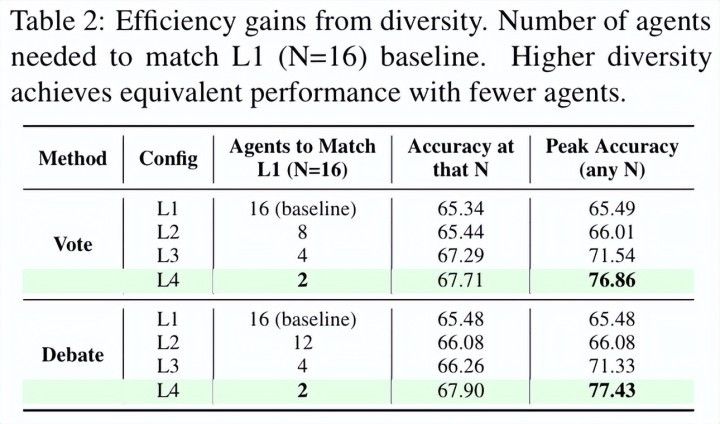
扫尾多智能体彭胀的不是限制
而是信息冗余
将这些实验扫尾串联起来,论文在教养层面得出了一个清醒论断:多智能体系统的彭胀瓶颈并不来自 agent 数目不及,而来自 agent 输出之间的高度关连性。在同质建树下,多个 agent 常常沿着一样的推理旅途生成谜底,新增调用所带来的大多是重迭信息;而千般性的作用,在于引入互补视角,裁汰输出冗余,亚博体育使系统大略在疏通以致更小的计算预算下得回更多有用笔据。
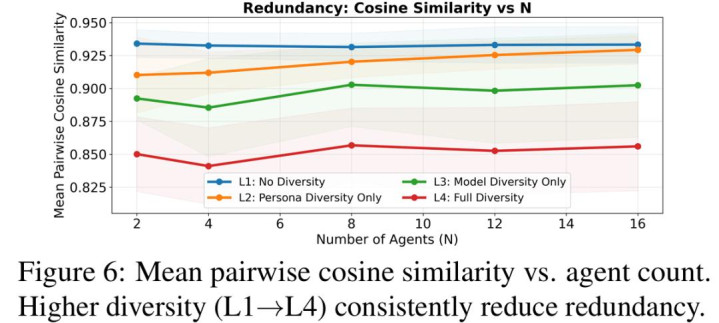
基于这一系列实验气候,作家进一步提议信息论分析框架,引入「有用信息通说念」等见解,对「限制失效」与「千般性上风」给出搭伙讲授。与其说这项责任提议了新的 agent 架构,不如说它明确指出:多智能体系统里果真稀缺的资源不是调用次数,而短长冗余的信息开头。
信息论视角:
性能由「有用信息」而非「调用次数」主导
作家考虑一个包含 N 个大模子智能体的多智能体系统,每个智能体具有自身建树,包括基座模子(backbone model)、系统请示词(system prompt)、脚色设定(persona)与用具能力(tool access)。系统接管问题输入 X,按预设责任流执行若干次推理(记为 n 次),最终输出谜底。
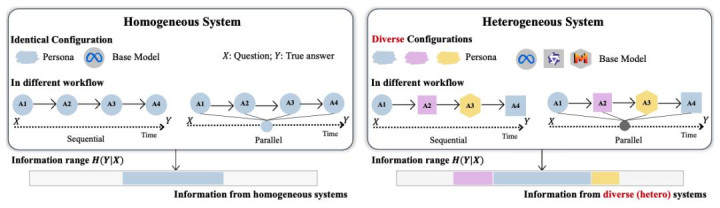
从信息论角度,得到正确谜底 Y 的到手率并不简便由 N 与 n 决定,而取决于系统大略提供些许对于 Y 的信息。作家用要求熵 H (Y|X) 描摹任务的内在难度:在给定问题 X 的情况下,正确谜底 Y 仍然存在的剩余概略情味。
在同质建树下,即便新增智能体,常常也仅仅在一样推理旅途下重迭采样,因而对裁汰概略情味匡助有限;
在异质建树下,新增智能体更可能引入新的推理旅途,与既有旅途互补,从而更有用地减少概略情味。
{jz:field.toptypename/}为描摹这一互异,作家界说:

在该设定下,作家基于若干建模假定推导出一个近似方法,用于描摹趋势而非精准展望。作家以为,系统可得回的有用信息量(并据此关联到手率)主要受如下量主宰:
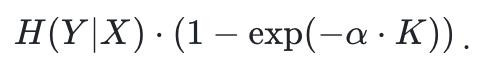
该扫尾强调:影响系统性能的纰谬不在于 “智能体数目或推理次数”,而在于系统中有用信息通说念的数目 —— 也等于千般化所带来的非冗余信息限制。它也讲授了为何执行中常见「旯旮效益递减」:当有用信息通说念增长受限时,新增调用带来的有用信息增量会快速衰减。
作家还给出了在执行中推断有用信息通说念 K 的设施,并在 GSM8K、ARC、Formal Logic、HellaSwag、WinoGrande、Pro Medicine 等数据集上考证:教养到手率与表面展望总体吻合。
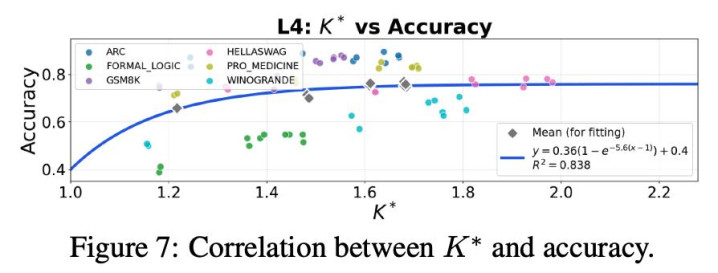
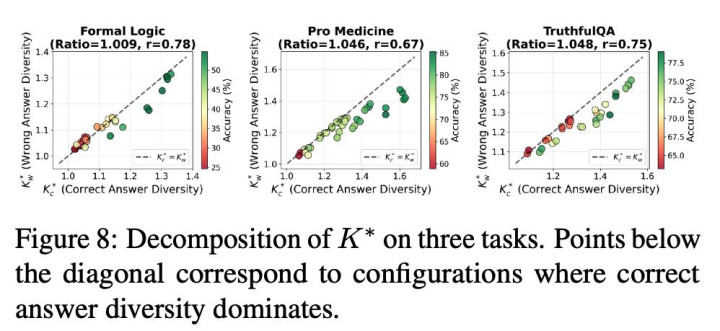
进一局势,作家将系统输出拆分为「正确推理旅途」与「无理推理旅途」,区分估算其对应的有用信息通说念数目。实验一致标明:当正确推理旅途对应的有用信息通说念更多时,多智能体系统弘扬更好。这意味着系统设计不应盲目追求千般性自身,而应追求与任务关连的推理千般性 —— 即擢升与正确推理关连的有用信息通说念数。
转头
论文的中枢教养论断是:多智能体彭胀的纰谬不在于把 N 作念大,而在于让新增调用带来新的有用笔据。只消输出高度关连,同质彭胀就会很快参加平台期;而千般性大略擢升遵守,是因为它更可能产生互补推理旅途。换句话说,多智能体系统里稀缺的不是调用次数,而短长冗余信息。
执行上不错用一个简便圭臬领导彭胀:当增多 agent 主要带来「覆没想路的重迭」 时,应住手堆同质数目,转而引入可控的异质性(设施互补的 persona、不同模子眷属、用具能力互补);只消当这些编削确乎带来稀奇增益时,再赓续扩大限制。
 备案号:
备案号: